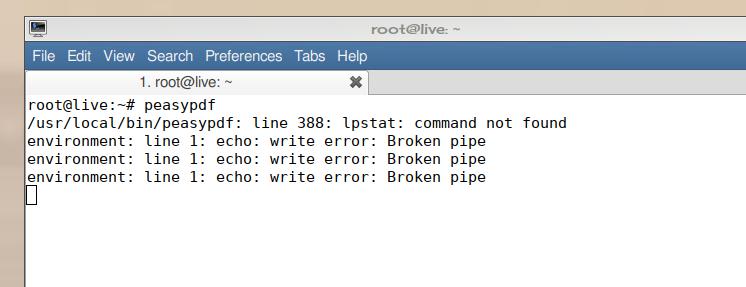
As in the images it seems that it performs the extract but I cannot find anything in the PDFextect folder and I have the following info in the peasypdf.log.
Can anyone advise me on a way to the solution?
thank you
sonia
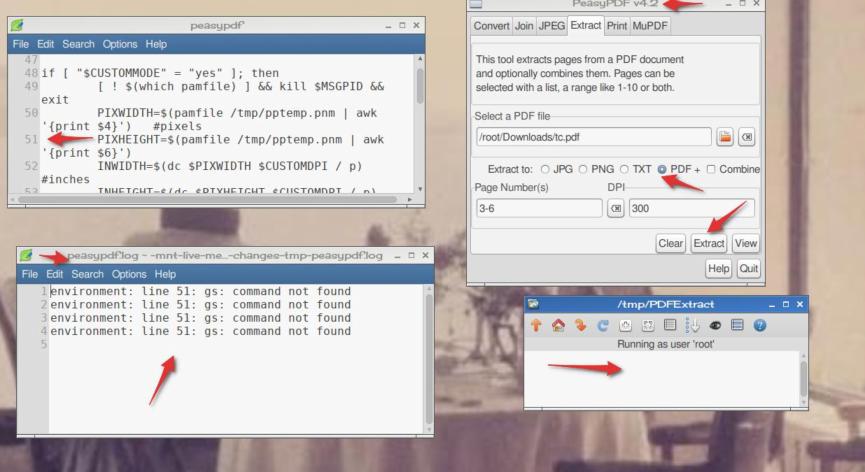
here from terminal, it looks like it extracts from these reports instead and pdfextract folder is empty.